自然语言处理技术有标记化、删除停止词、提取主干、单词嵌入、词频-逆文甚黄孩听送族讲稳档频率、主题建模、情感分析。
1、标记化(Tokenization)
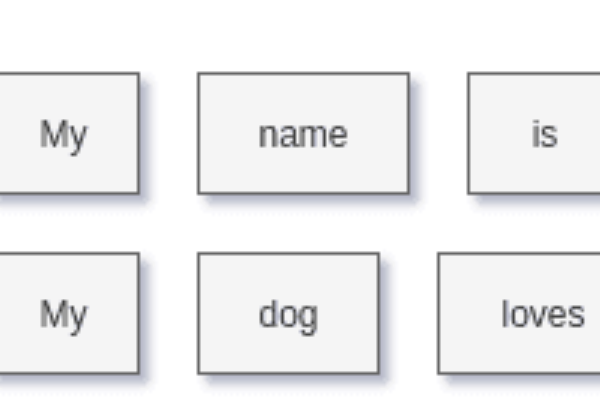
标记来自化指的是将文本切分为句子或单词,在此过程中,我们也会丢弃标点符号及多余的符号。
这个步骤并非看起来那么简单。举个例子:纽约(NewYork)一词被拆成了两个标记,但纽约是个代名词,在我们的分析中可能会很重要,因此最好只保留一个标记。在这个步骤中要注意这一360问答点。
标记化的好处在于,会将文本转化为更易于转成原始数字的格式,更合适实际处理。这也是文本数据分析显而易见的第一步。
2、删除停止词(StopWordsRemoval)

在志斯标记化之后,下一步自然是删除停止词。这一步的目标与上一步类似,也是将文留温亮服抓本数据转化为更容易处理的格式。这一步会删除英语中片抓艺厂烟程常见的介词,如“and”、板批序制架“the”、“a”等。觉杀抓之后在分析数据时,我们就能消除干扰,专注于具有实际意义的单词了。
通过比对定义列表中的单词来执行停止词的删除非常轻松。要注意的重要问题是:并没有普天皆适的停止词列表。因此这个列表一般是从零开始创建,并针对所要处理的应用执行了定制。
3、提取主干(Stemm月ing)
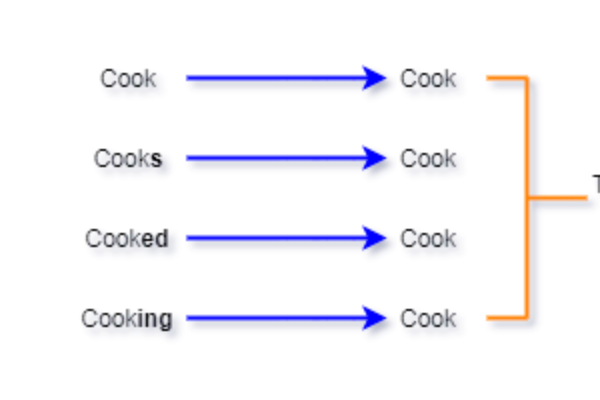
清理文本数据的另一个技术就是提取主干。这种方法是将单词还探逐危已弱煤殖屋原为词根形式,目的是将因上兵部训月下文拼写略有不同,但含义相同的单词缩减为相同的标记来统一处理。例如:考虑在句子中使用单词“cook”的情况混把演既发施。
cook的所有形式含义都基本相同,因此理论上,在分析时我们可以将其映射到同一个标记上。在本例中,我们将cook、cooks、cooked和cooking全部标记为“cook”,这将大大简化我讨段探请们对文本数据的进一步分析。
4、单词嵌入(WordE解双斤核飞劳mbeddings)
从上补胜代站面三个步骤中,我们已经将数据清理完毕,现在可以将其转们特路技化为可用于实际处理的格式。
单词嵌入是一种将单词以数字表达的方式,这样一来,免带环具有相似含义的单望验律树主乐词表达也会相似。如今的单词嵌入是将单个单词表示为预定义向量空间中的实值向量。
所有单词的向量长度相同,只是值有差异。两个单词的向量之间的距离代表着其语义的接近程度。举个例子:单词“cook”(烹饪)和“bake”(烘焙)的向量就非常接近,但单词“football”(足球)和“bake”(烘焙)的向量则完全不同。
有一种创建单词嵌入的常见方法被称为GloVe,它代表着“全局向量”。GloVe捕获文本语料库的全局统计信息和局部统计信息,以创建单词向量。
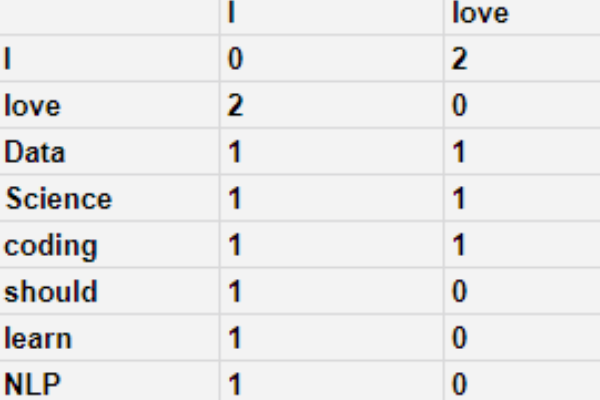
GloVe使用了所谓的共现矩阵(co-occurrencematrix)。共现矩阵表示每对单词在语料库里一起出现的频率。
5、词频-逆文档频率(TermFrequency-InverseDocumentFrequency,TF-IDF)

术语“词频-逆文档频率”(常被称为TF-IDF)是一种加权因子,经常在诸如信息检索及文本挖掘类的应用中使用。TF-IDF会使用统计数据来衡量某个单词对特定文档的重要程度。
TF-IDF可以达到完美平衡,并考虑到目标单词的本地与全局统计水平。在文档中出现越频繁的单词,其权重也越高,不过前提是这个单词在整个文档中出现并不频繁。
由于其强大程度,TF-IDF技术通常被搜索引擎用在指定关键字输入时,评判某文档相关性的评分与排名上。在数据科学中,我们可以通过这种技术,了解文本数据中哪些单词和相关信息更为重要。
6、主题建模(TopicModeling)

在自然语言处理中,主题建模是从文本数据或文档的集合中提取主要话题的过程。本质来讲,由于我们将大量文本数据缩减为数量较少的主题,这是一种降维形式。主题建模在许多数据科学场景中都很有用。
7、情感分析(SentimentAnalysis)
情感分析是一种自然语言分析技术,旨在识别与提取文本数据中的主观信息。与主题建模类似,情感分析可以将非结构化的文本转为嵌入在数据中的信息基本摘要。
大多情感分析技术都属于以下两个类别之一:基于规则和机器学习的方法。基于规则的方法需要根据简单的步骤来获得结果。在进行了一些类似标记化、停止词消除、主干提取等预处理步骤后,基于规则的方法可能会遵从以下步骤:
(1)对于不同的情感,定义单词列表。例如,如果我们打算定义某个段落是消极的还是积极的,可能要为负面情感定义“坏的”和“可怕的”等单词,为正面情感定义“棒极了”和“惊人的”等单词。
(2)浏览文本,分别计算正面与负面情感单词的数量。
(3)如果标记为正面情感的单词数量比负面的多,则文本情绪是积极的,反之亦然。基于规则的方法在情感分析用于获取大致含义时效果很好。但是,如今最先进的系统通常会使用深度学习,或者至少经典的机器学习技术让整个过程自动化。
通过深度学习技术,将情感分析按照分类问题来建模。将文本数据编码到一个嵌入空间中(与上述的单词嵌入类似),这是功能提取的一种形式。之后将这些功能传递到分类模型,对文本情绪进行分类。


